Cursor is an AI code editor that lets you give its agent persistent instructions via rules files. Those rules are not free documentation: they load into the agent's context on every turn that matches their trigger, and you pay for them every time. Most setups fail the same way: too many rules, on too many topics, and the agent still ignores half of them.
What you are actually paying for
Every agent turn has a context budget. Rules are a fixed cost you pay before the conversation starts. A rule with alwaysApply: true loads on every single turn, regardless of what you're working on. A glob-scoped rule loads on every turn that touches a matching file. Both cost real tokens, and those tokens add up across a long session.
The model already knows how to write Go, Python, TypeScript, or whatever language your repo uses. It knows generic best practices. It knows what clean code means. You only win on a rule when it changes behavior the model would not reliably produce on its own without it.
That is the question to ask before writing any rule: "Would the model do the wrong thing here without this?" If the answer is "probably not," don't write it. Rules are not a place to record things you believe are true about good engineering. They are instructions that must earn their token cost by changing specific behaviors in specific situations.
Five containers for agent instructions
Before deciding what goes in rules, understand what options you have. Rules are one layer of five, and they are the right choice for a narrow slice of what teams try to put in them.
| Container | When it loads | Best for |
|---|---|---|
| Constitution (.mdc, alwaysApply: true) | Every turn, always | Non-negotiable safety rules and git policy |
| Scoped rules (.mdc, glob-scoped) | When matching files are in context | Repo-specific behavioral deltas per file type |
| Skills (SKILL.md, on demand) | Only when explicitly triggered by name | Multi-step workflows you run repeatedly |
| Docs (referenced by @) | Only when @-mentioned | Architecture decisions, API references |
| CI (linters, tests, gates) | On commit or PR | Standards that must not depend on memory |
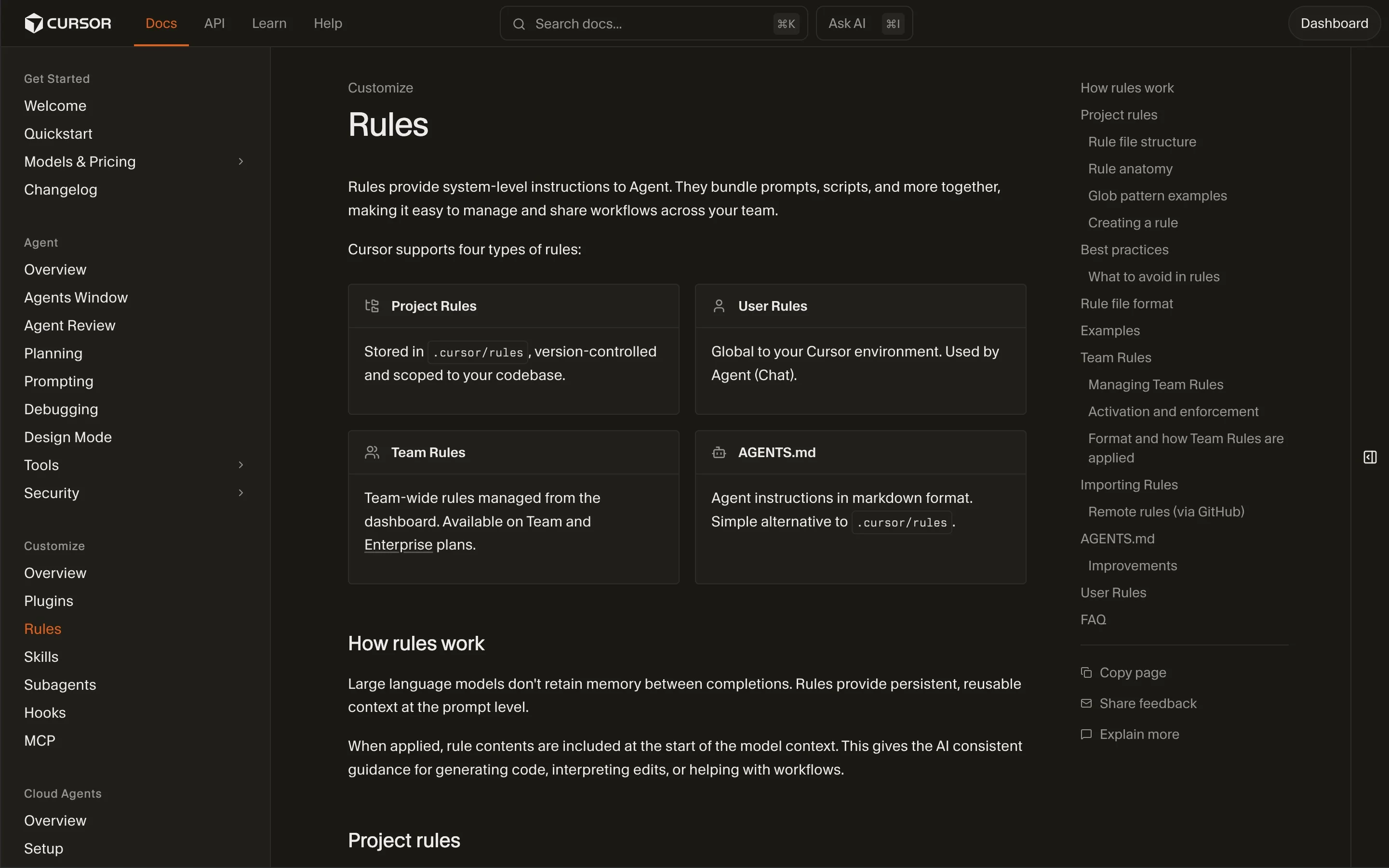
The Cursor rules documentation describes four official rule types: project rules, user rules, team rules, and AGENTS.md. The five containers above map to those but split the always-on constitution out as a distinct tier, because it has different cost and risk characteristics from file-scoped behavioral rules.
The single biggest mistake teams make is routing everything through rules. Rules should be your thinnest layer. CI enforces what cannot be left to memory. Docs provide reference when referenced. Skills handle workflows. Rules handle the narrow band of behavioral constraints that apply to every session or every file of a certain type.
Your constitution: the only file that should be always-on
One file should use alwaysApply: true. One. This is your constitution: the non-negotiables that must hold on every turn, no exceptions. Safety constraints, git policy, scope discipline. Everything that, if violated, creates a real problem rather than a style inconsistency.
Here is what a production constitution actually looks like. I built this for a repo where multiple engineers run AI agents simultaneously, and where a mistake in production config or a credentials leak carries serious consequences:
---
description: Agent safety and change discipline
alwaysApply: true
---
# Agent safety
- Never commit secrets, tokens, or credentials. Use environment variables or a secrets manager.
- No destructive database operations without explicit approval. No DROP or TRUNCATE in migrations without human review.
- No production config, feature flags, or infrastructure changes unless explicitly requested.
- Do not skip or disable tests to green CI. Fix the root cause. No --no-verify unless the user asks.
- No large unrelated refactors. One concern per PR. Plan before changing more than three files or adding new dependencies.
- Read existing code before editing. Match repo patterns over model defaults.
- When changing observability: update README and any relevant dashboards.That is 16 lines including frontmatter. It loads on every turn. The cost is justified because these constraints apply everywhere, the failure modes if violated are serious, and the model will occasionally drift toward convenience over safety without them. A model completing a task will sometimes take the path of least resistance: skip a test that's inconvenient to fix, add a credential to a config file because it's the quickest way through. These rules exist to prevent that drift.
Notice what is not in this file: no coding philosophy, no style guide, no language-specific advice. Those go elsewhere or not at all.
Scoped rules: repo-specific deltas only
Everything that is not a safety or git constraint should be scoped with globs, not marked alwaysApply: true. A glob-scoped rule loads only when a matching file is in context, so you are not paying for Go conventions while working on a Python data pipeline.
Here is a minimal example for a Go service:
---
description: Go conventions for this repo (not generic Go)
globs: "**/*.go"
alwaysApply: false
---
- Errors: wrap with context at boundaries using fmt.Errorf("...: %w", err). Use sentinel errors in domain/.
- Logging: slog only. No fmt.Println in production paths.
- HTTP: handlers in internal/api. Business logic never imports net/http.
- DB: queries in internal/store. No raw SQL outside the store package.Four lines of actual content. Note what this file does not include: no recap of how Go error handling works, no explanation of what a handler is, no description of the language conventions any Go developer already knows. The model knows all of that. This file encodes only the deviations from generic good practice that are specific to this repo's structure.
The test for whether something belongs in a scoped rule: if you deleted this rule and asked an experienced developer to work in this repo for the first time, would they know this from looking at the code itself? If yes, the rule is redundant. If no, it might belong.
Keep individual rule files under 50 lines. One concern per file. A single 200-line omnibus rule file is harder to maintain and harder to reason about than four focused files of 30-40 lines each.
Skills are not rules
If you find yourself writing a rule that says "when the user asks you to add a new API endpoint, follow these steps: first read X, then create Y, then update Z and W" - that is a skill, not a rule.
Skills live in .cursor/skills/ as SKILL.md files. They load only when explicitly triggered by name in the chat, not on every turn. A workflow that you trigger once a week costs zero tokens on the other 499 turns where you don't. The same workflow written as a scoped rule with broad globs costs tokens every time you open a matching file.
The distinction is straightforward: a rule is a behavioral constraint that applies passively, in the background, on every matching turn. A skill is a workflow that you invoke deliberately when you need it. If you're writing a sequence of steps, it's a skill. If you're writing a constraint, it's a rule. If a linter or CI check can enforce it, it's neither.
What not to put in rules
The most expensive rules are the ones that seem obviously valuable and do nothing. Here are the patterns I see most often:
Generic coding philosophy
"Write clean, readable code." "Think before you code." "Prefer simple over complex." These are things the model already does. They consume tokens without changing behavior. The model is not ignoring them because it forgot; it just does them anyway. If you add a rule and nothing changes, that rule is dead weight.
Things linters already enforce
If your CI runs gofmt, eslint, or TypeScript strict mode, you don't need a rule telling the agent to follow those standards. The linter is the check; the CI gate is the enforcement. A rule saying "format your Go code correctly" is paying twice for the same guarantee, and if the agent does format incorrectly, it's the CI that catches it, not the rule.
Documentation copy-pasted into rules
Do not paste your README, your architecture document, or your API reference into a rule file. Rules are not a knowledge base. Use @-mentions to bring documents into context when needed. The cost of an @-mentioned file is paid once, when you mention it. The cost of that same content in an alwaysApply rule is paid on every turn for the entire session.
Multiple rules saying the same thing
If you have three rules that all say some version of "keep changes small and focused," consolidate them into one line in your constitution or delete them entirely. Redundancy does not make a constraint more effective. It makes your rule set harder to audit and more expensive to run.
"Remember to..." instructions
The model does not remember between sessions. "Remember to update the changelog" is not a rule; it is wishful thinking. If you need something to happen consistently at the end of every PR, put it in a PR template or a CI check. If you need it to happen during a specific workflow, put it in a skill. If it needs to happen on every single turn regardless of context, put it in the constitution. Otherwise, cut it.
A four-question test
Before adding anything to any rule file, run it through these four questions:
- Would the model do the wrong thing here without this? If not, don't add it.
- Does it apply everywhere, per file type, or only in specific workflows? Everywhere means constitution. Per file type means scoped rule. Specific workflow means skill.
- Can a linter, test, or CI check enforce it instead? If yes, use that. CI does not forget; rules sometimes do not fire.
- Is this specific to this repo, or is it generic advice the model already knows? If generic, cut it.
Most candidates fail at question 1 or question 3. A rule that passes all four questions is genuinely worth writing. Most of what ends up in bloated rule files would fail at the first question if the team asked it honestly.
The other thing to watch: do not add rules preemptively. Add a rule when you have observed a specific failure that the rule would have prevented. Not when you can imagine a failure. When you have seen it. This keeps your rule set lean and ensures every line earns its place.
What to do now
Open your current .cursor/rules/ directory. For every line in every file marked alwaysApply: true, ask: did the agent actually violate this before I added it? If you cannot say yes from memory, cut the line. Then count what's left. If your always-on rules are more than 25 lines total, they are too long.
If you're starting from scratch: write only your constitution. Safety, git policy, scope discipline. Keep it under 20 lines. Add scoped rules only after you observe a specific behavioral problem in a specific file type. Add skills for workflows you run more than once a week. Leave everything else to the linter and CI.
The right number of rules is the minimum that prevents the failures you have actually seen. Not the failures you can imagine.